编译打包
Spark支持Maven与SBT两种编译工具,这里使用了Maven进行编译打包;
在执行make-distribution脚本时它会检查本地是否已经存在Maven还有当前Spark所依赖的Scala版本,如果不存在它会自动帮你下载到build目录中并解压使用;Maven源最好配置成OSChina的中央库,这下载依赖包比较快;
耐心等待,我编译过多次所以没有下载依赖包,大概半个小时左右编译完成;注意:如果使用的是Java 1.8需要给JVM配置堆与非堆内存,如:export MAVEN_OPTS="-Xmx1.5g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m";
进入Spark根目录下,执行:
./make-distribution.sh --tgz
--tgz 参数是指编译后生成tgz包
- PHadoop 支持Hadoop
-Pyarn :支持yarn
-Phive :支持hive
--with-tachyon:支持tachyon内存文件系统
-name:与--tgz一起用时,name代替Hadoop版本号
./make-distribution.sh --tgz --name 2.6.0 -Pyarn -Phadoop-2.6 -Phive
开始编译检查本地环境,如不存在合适的Scala与Maven就在后台下载;
编译中:
编译完成并打包生成tgz:
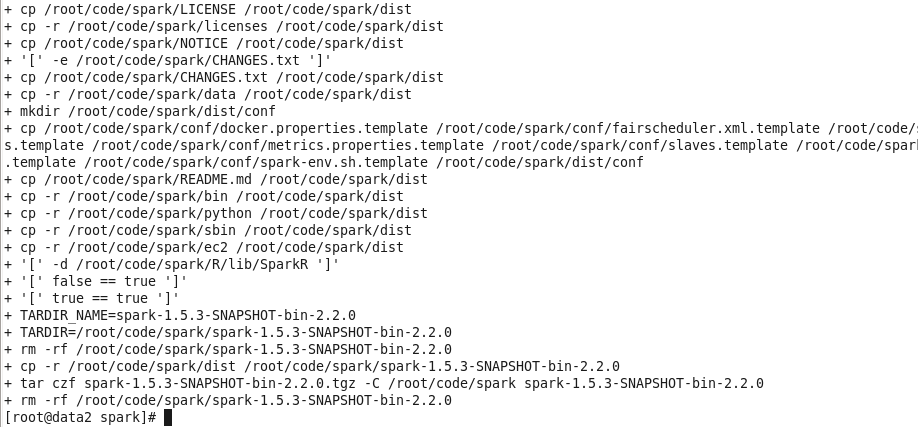
编译完成后把生成的文件拷贝到当前Spark的dist目录中并且打包生成spark-1.5.3-SNAPSHOT-bin-2.2.0.tgz文件;

FEATURED TAGS
Agent
大模型
ChatGPT
HA
智能家居
LSM
Linux
Dapr
开发
插件
Linux,虚拟机,ubuntu
缓存
图片
Flink
反射
内置函数
go
限流
大数据,Spark,Kafka
面向对象
镜像
docker,hadoop,镜像
kafka,java
求导
链式法则
微积分
源码
快照
协议
ZooKeeper
ZAB
tomcat
Hadoop
Spark
python
自动微分
React Native
React
Node.js
Android
Kafka
lambda
jvm
rasp
框架
SPI
asm
maven
idea
依赖管理
module
helm
逻辑回归
S函数
IOS
Fiddler
Andriod
Protocol Buffer
kryo
车联网,大数据,神经网络
字节序
最小二乘法
线性代数
线性回归
最大似然法
网络编程
大数据
树莓派
Raspbian
redis
海南
分析
人口
函数式编程
clojure
线程
并行
actor
红黑树
数组
动态数组
tcp
编程
markdown
二叉搜索树
AVL树
数据结构
golang
梯度下降法
skaffold
k8s
机器学习
选法
一致性
算法
分布式
paxos
Raft
一致性协议
引擎
容器
通信
微服务
Kubernetes
docker
文件系统
NFS
神经网络
神经元
深度学习
poi
反向传播
java
并发模型
并发
多线程
Scala