对于个人或小公司有部署使用本地大模型的需求,但由于业务需求直接部署一个开源的通用大模型又不满足需求。这时常见的解决方案是使用RAG方案或微调模型方案。微调是使用领域知识训练模型,使模型其具备相应的领域知识能力。微调后模型可独立生成相应的领域知识,无需再通过RAG方案问答时通过上下文提供对应的领域知识。
模型私有化部署对显卡资源的消耗比较高,对于一个4B模型BF16部署的资源已经达到9GB(4B×2×10⁹ ×1.2≈9 GB),对于14B模型最少需要32GB显存需求。就算是部署低精度或量化版模型一个基本可用的14B模型也最少需要16GB左右显存。
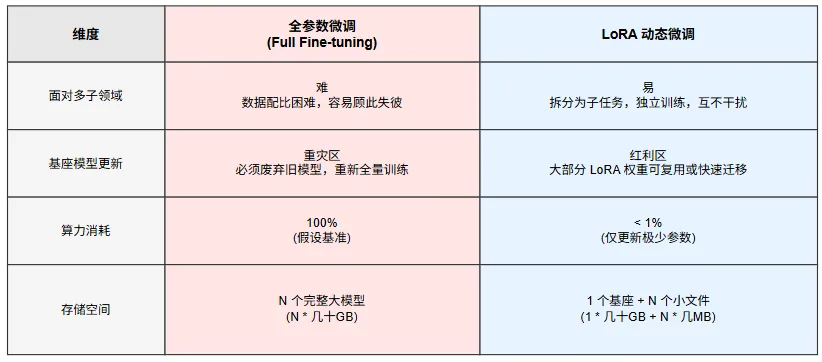
对于这种规模的显存需求对于个人或小公司来说同时部署N个全量微调的专家模型似乎有点难。如果部署10个微调的领域专家模型需要的资源是N倍的显存资源(10 * 9GB =90GB), 这已经是超过一张A100的显存资源也超过3张4049(24GB)卡的资源。
微调
微调除了全参数微调还有参数高效微调(PEFT),通过高效微调LoRA后根据微调的参数规模适配器的大小只有几十MB到几百MB不等。前面文章我们也介绍过LoRA,这边再简单介绍下LoRA的基本原理。
LoRA (Low-Rank Adaptation) 是目前最主流的大模型高效微调(PEFT, Parameter-Efficient Fine-Tuning)技术。它的核心思想是:冻结预训练模型的权重,仅在各层中注入可训练的低秩矩阵(Low-Rank Matrices)。
W = W₀ + ΔW = W₀ + BA
其中:
W₀ 是冻结的预训练权重(维度 d x d)。
B 是 d x r 的矩阵(初始化为 0)。
A 是 r x d 的矩阵(高斯初始化)。
r 是秩(Rank),通常远小于 d(通常取8~128)。
优势:
显存极低: 仅需训练不到 1% 的参数。
不破坏原模型: 原模型权重不变,LoRA 只是作为一个“外挂”插件。
便于切换: 同一个基座模型可以加载不同的 LoRA 权重来适应不同任务(如一个负责写代码,一个负责写小说,一个负责法律知识),无需重新加载大模型。
成本低:不仅可以在训练时显著降低显存占用和训练时间,还保持与全量微调相当的效果。

专家模型
上面介绍了PEFT微调的一种技术LoRA微调原理,本节主要介绍LoRA技术实际应用。通过LoRA微调后会生成LoRA适配器此适配器的大小与微调时训练的参数规模相关通常几十MB到几百MB不等,LoRA适配器不严谨的可称为专家模型。 LoRA适配器通常有两种使用方式:
- 静态合并:LoRA适配器合并到基座模型,基座模型参数改变,不可再分离。
- 动态加载:LoRA适配器单独存储,基座模型参数不变,使用时加载。
LoRA 动态加载不只是技术选择,还是应对模型快速迭代的最佳经济策略。 LoRA可解决领域细分的颗粒度问题。不单是不同领域行业知识需要分开微调,单一行业(如法律)内部也存在民事、刑事、合同法、涉外法等等差异巨大的子领域,直接哪这些行业知识去微调去全参数微调一个模型或许也能微调好,但工程难度不小,消耗的资源也不少。
打破“基座更新即重练”的成本诅咒,按目前行业的发展每半年一代新模型发布速度,每当基座模型(Base Model)更新又要投入大量的资源去全参数微调更新专家模型,如果使用的是LoRA专家模型,只需基于新基座快速迁移与微调轻量级的适配器(Adapter)。LoRA 将模型的维护升级成本从“指数级”降低到了“线性级”。
工程实践
多LoRA架构的核心在于基座共享,插件热拔插。在显存中,我们只保留一份巨大的基座模型权重,而针对不同领域的 LoRA 模块(仅占极小显存)则根据用户请求实时加载或切换。还可以使用基座模型提供通用的知识服务。
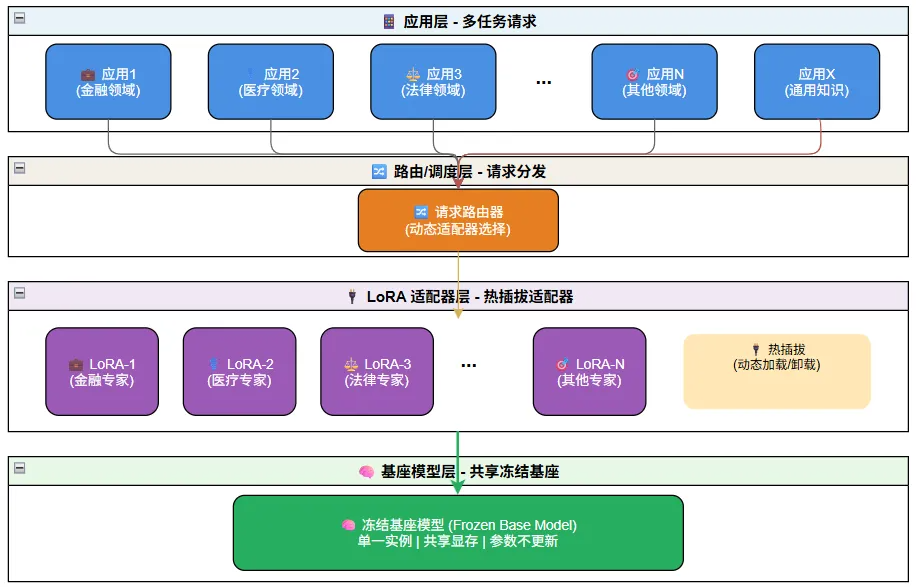
整个多LoRA架构系统像一个现代化的综合医院:
- 应用层(挂号处): 接收病人(请求)。
- 路由层(分诊台): 决定病人去哪个科室(选择哪个 LoRA),或者只是去药房买点感冒药(基座直通)。
- 显存管理(调度中心): 确保医生(LoRA 参数)已经就位。
- 推理引擎(诊疗室): 医生(LoRA)配合基础医疗设施(基座模型)进行诊断。
注意上图中LoRA适配器是旁路(Sidecar)权重,它是挂在基座模型上的,数据流直接进入“基座+LoRA”的组合体。LoRA 和基座是并联计算(或者说数学上的权重相加),而不是串联处理。
查看当前大模型推理服务存在多少模型,下面可以看到存在一个基座模型Qwen3,三个LoRA专家模型。
http://192.168.1.1:13000/v1/models
{
"object": "list",
"data": [
{"id": "../../models/Qwen3-4B","object": "model","created": 1765038561,"owned_by": "xxx","root": "../../models/Qwen3-4B","parent": null,"max_model_len": 40960},
{"id": "law_lora","object": "model","created": 1765038561,"owned_by": "xxx","root": "../../lora/LoRA-and-MoE/law/law-lora-model-4B-1206","parent": "../../models/Qwen3-4B","max_model_len": null},
{"id": "starTrek_lora","object": "model","created": 1765038561,"owned_by": "xxx","root": "../../models/Qwen3Guard-StarTrek-Classification-4B","parent": "../../models/Qwen3-4B","max_model_len": null}
{"id": "hn_lora","object": "model","created": 1765038561,"owned_by": "xxx","root": "../../models/hn-lora-Qwen3-4B","parent": "../../models/Qwen3-4B","max_model_len": null}
]
}
在使用时只需要选择某个LoRA模型或不指定LoRA专家模型,直接使用基座模型;
response = client.chat.completions.create(
model="Qwen3-4B",
messages=[
{"role": "user", "content": inference_prompt},
],
temperature=0,
max_tokens=1024,
#可不使用lora
extra_body={
"lora_path": "law_lora",
}
)
现在业内多LoRA部署有多种成熟的方案,多LoRA专家模型部署推理主流方案如下:
- vLLM: 目前最流行的推理框架之一,原生支持 Multi-LoRA serving。它可以在处理请求时动态地为不同请求应用不同的 LoRA 适配器,而无需重新加载基座模型。
- Hugging Face TGI (Text Generation Inference): 提供了对多个 LoRA 适配器的支持。
- LoRAX (LoRA Exchange): 专门为服务数千个 LoRA 模型而设计的推理服务器,优化了 LoRA 的换入换出机制。
- SGLang:原生支持Multi-LoRA serving,请求时动态的为不同应用路由到不同的LoRA适配器。
- LoRAX:号称一个GPU上能部署上百LoRA适配器模型。
未来
未来也未必是未来。
目前除了已经成熟的基于LoRA外挂适配器权重的多专家模型方案外,还有一中学术界还在探索中没那么成熟的MoE-LoRA方案,混合专家融合的LoRA方案。
LoRA微调可以理解为训练了N个独立的LoRA(针对不同数据集),创造了N个专家。
- LoRA A:只用代码数据训练(Code Expert)。
- LoRA B:只用数学数据训练(Math Expert)。
- LoRA C:只用小说数据训练 (Creative Writing Expert)。
MoE-LoRA可以理解为把这 N 个 LoRA 塞进一个模型里并使用门控控制。 目前独立LoRA存在一个问题就是需要提前知道任务级或会话级类型。一旦你选定了 LoRA(代码专家),在接下来的生成中,它就无法处理其他领域的知识,不适合复合型任务。
而MoE-LoRA则不存在上面问题,模型内部有一个 门控(Gating),针对每一个 Token(词元) 进行决策,可以瞬间切换LoRA专家,一会使用代码专家 LoRA一会使用文学专家LoRA。模型是一个既懂着又懂那的缝合怪天才。一个句子的生成过程中动态调用不同的能力,这是独立 LoRA 绝对做不到的。有一种专家间的软协同能力。