Agent 开发的几乎都绕不开一个念头:智能体能不能越用越聪明?具体来说,能不能做到:
把做过的事自己沉淀下来
用户下次不用再把同一套流程教一遍
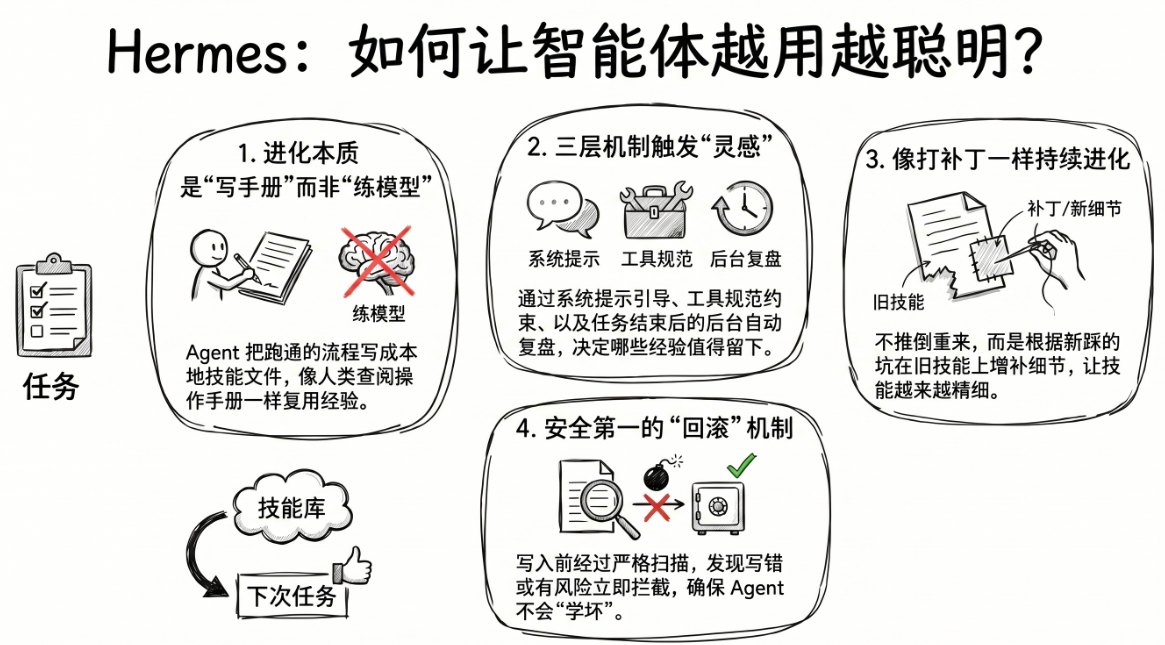
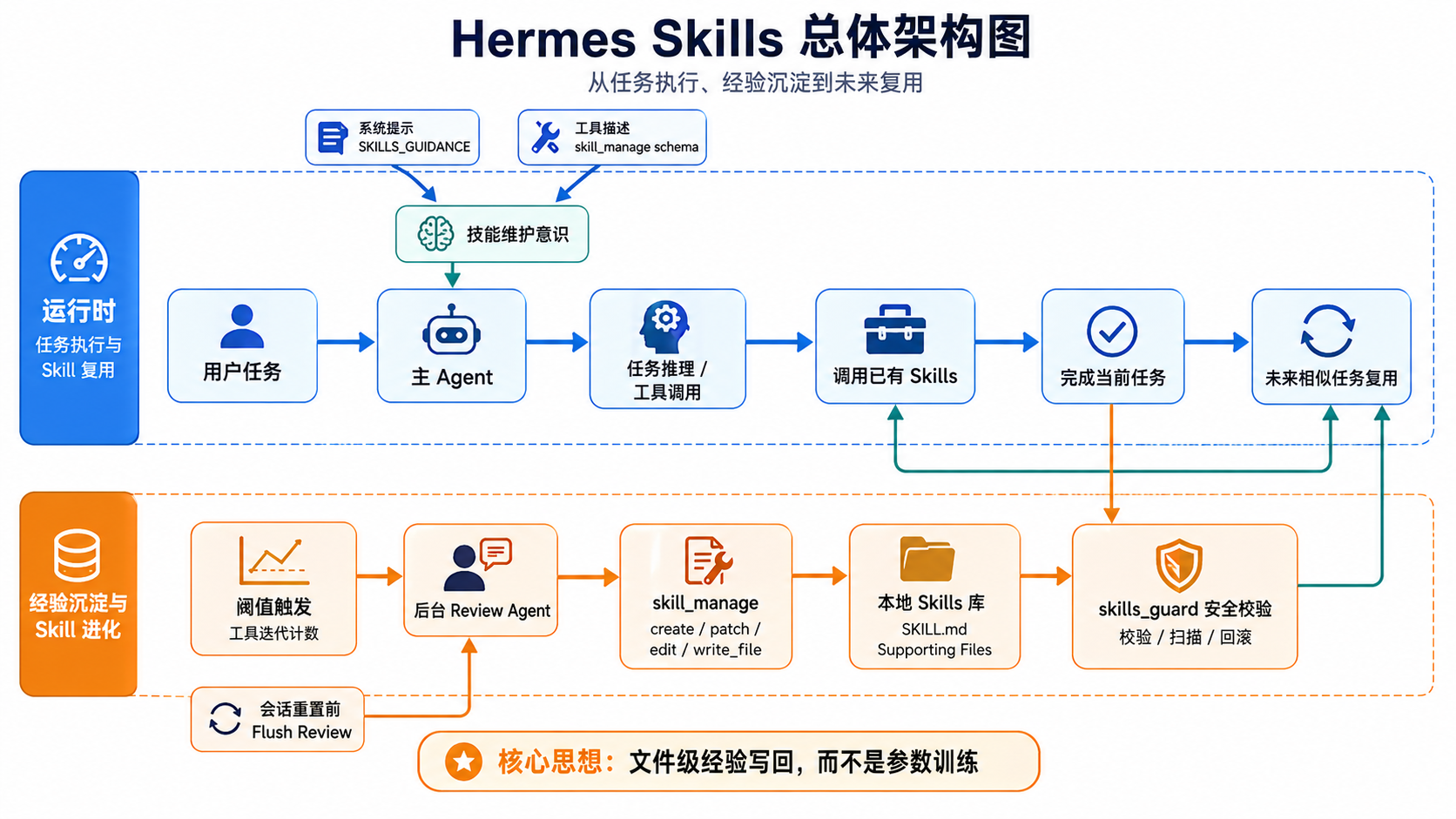
Hermes 对这个问题的处理没有往玄学上飘,也没吹嘘自己在后台偷偷训练新模型。它做得很朴素,也很工程化:每当 Agent 在任务里摸索出一套可以复用的做法,就通过 skill_manage 把这套做法写回本地技能文件。下次遇到类似任务,再把它拿出来继续用、继续改。
Hermes 的技能进化,不是参数层面的学习,更不是凭空长出什么新能力。它更像是把一次任务里跑通的经验,整理成一份能随时查阅、修改、甚至回滚的操作手册。
下面顺着这条链路拆开看一看。
Hermes 里”自动创建技能”的真实路径
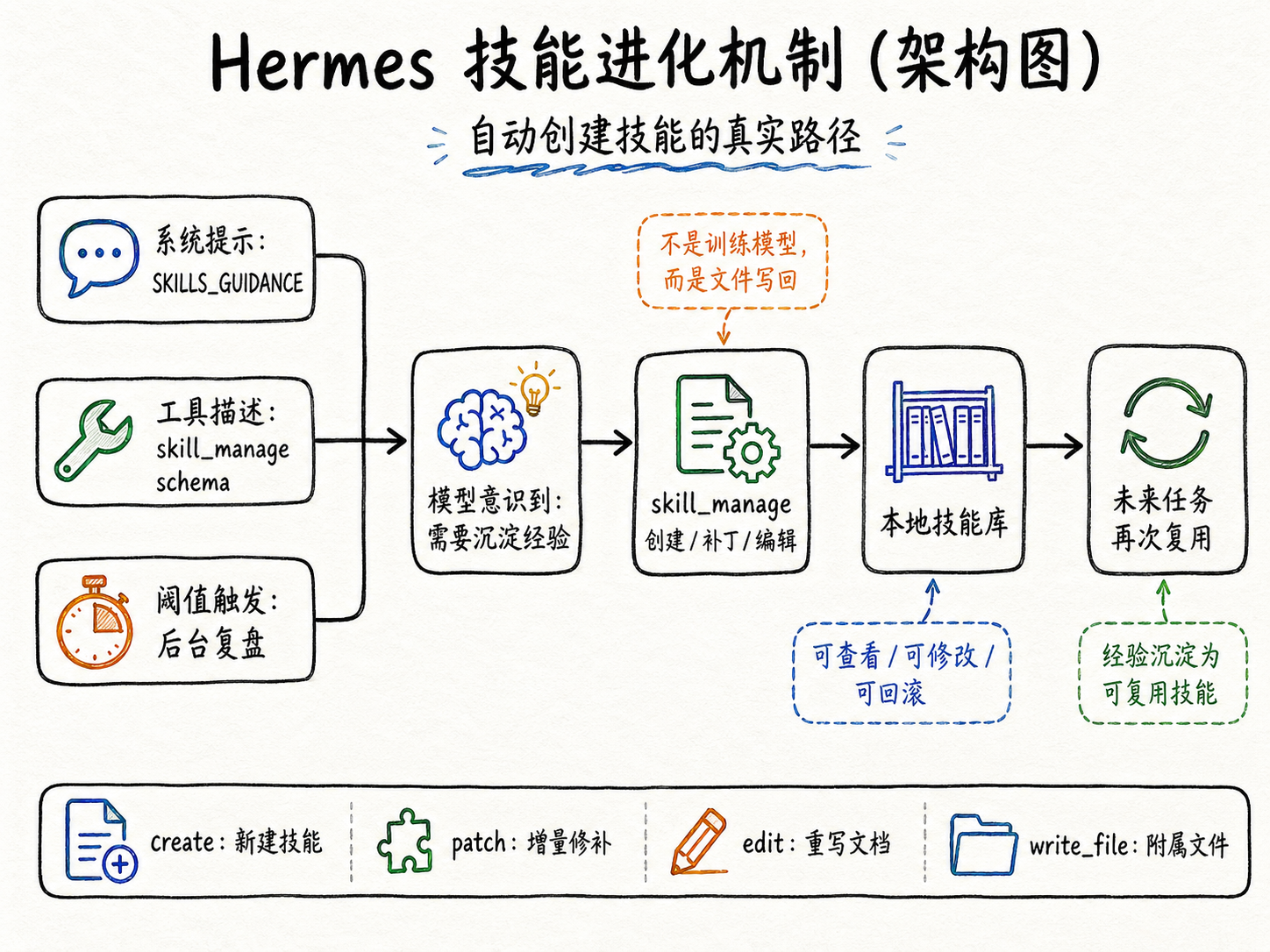
自动创建技能:本质是文件写回,不是训练
Hermes 所谓的自动生成技能,本质上是一套工具调用流程,而不是训练流程。
Agent 并不会把一次任务丢给某个学习器,然后在模型参数里“长”出新能力。它做的是:
1. 任务进行时, 提醒模型尽量使用和维护技能;
2. 任务结束后, 回头审视这次有没有值得复用的流程;
3. 如果有, 就调用 skill_manage() 创建新技能,或者给旧技能打补丁;
4. 把结果写回本地技能目录, 让后面的会话可以直接复用。
所以 Hermes 的“进化”,准确来说是文件层面的经验写回。
听起来当然没有“模型自我学习”那么高级,但好处很实在:它可控。
它学到了什么,你能打开文件直接看。
它写到了哪里,你能精确定位。
它有没有写坏,你可以审查、回滚、再改。
下一次为什么做得更顺,也都有迹可循。
为什么能进化?经验有地可写,且支持打补丁
很多 Agent 系统并不是发现不了经验,而是发现之后没地方存储处理。
这次调通了一套部署流程,下次还得重新琢磨;这次踩过一个环境坑,下次换个会话又踩一遍。问题不是在于“有没有经验”,如果用户没有主动把本次流程固化为Skills就等于是“经验有没有被系统接住”。
Hermes 把这件事做成了一条明确的写回路径,skill_manage() 支持的操作包括:
create:创建一个新技能
patch:给已有技能打补丁
edit:重写 SKILL.md
write_file:给技能增加附属文件
remove_file、delete:删除内容
最值得关注的是打补丁。
Hermes 不鼓励 Agent 一上来就重写整份技能文档,而是更偏向“补一小段”。这更接近真实的维护习惯:任务里发现了一个新坑、一个命令差异、一个验证步骤,就把它追加或修正到相应位置。
这样做有几个实际好处:token 消耗更小,修改范围更窄,更适合持续修补那些从真实任务里冒出来的细节。并且它的打补丁不是死板的字符串替换,底层用了模糊匹配,模型不需要精确记住原文里的每个空格,只要上下文能对上,就有机会把补丁打到正确位置。这就是它能**“边用边修”**的原因。
自动创建不靠开关,而是三层机制叠在一起
Hermes 的技能进化不是靠某个神秘按钮触发的,更像是三层提示和流程叠加出来的结果。
1. 系统提示词持续提醒 系统提示会反复提醒模型两件事:复杂任务结束后,考虑要不要保存成技能;使用技能时,如果发现过时、缺漏或错误,及时打补丁。这会让模型不只盯着解决眼前问题,也会被引导去思考“有什么值得留下”。
2. 工具的 schema 告诉它“怎么保存”
skill_manage 的 schema description 里有详细的操作规范:什么情况适合创建,什么情况更适合打补丁,什么样的技能才算质量过关,创建和删除前最好确认用户意图。Hermes 不仅告诉模型“你可以保存经验”,还告诉它“别乱写,尽量这样写”。
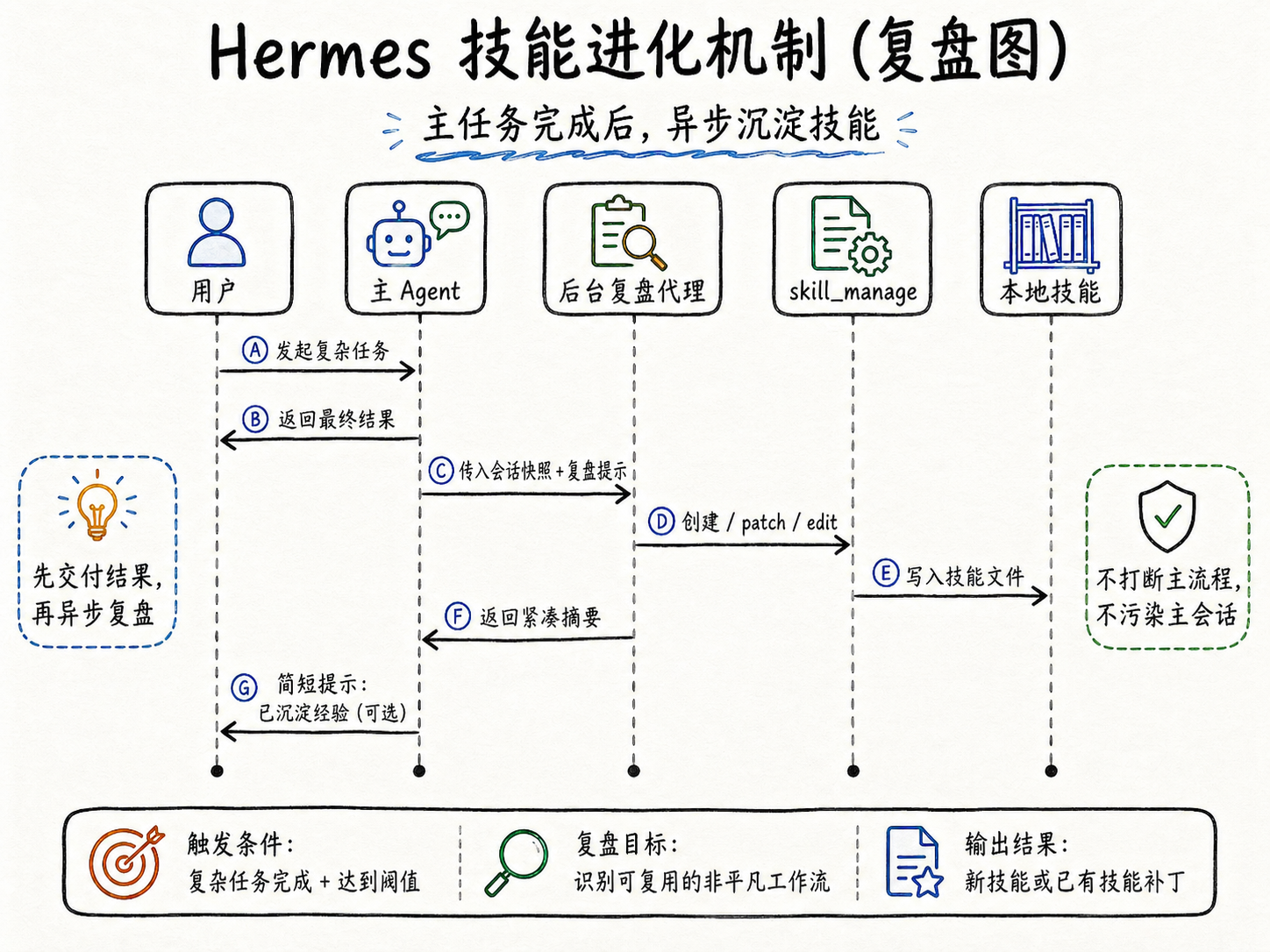
3. 后台复盘把“想一想”变成固定流程
真正把这套机制推起来的,是 run_agent.py 里的后台复盘。Hermes 会维护一个技能计数器,当达到阈值,主任务完成后会启动一个后台复盘代理。这个代理不直接跟用户聊天,而是拿着当前会话快照加上复盘提示,专门判断“有没有值得沉淀成技能的非平凡工作流”。有就创建或更新,没有就安静退出。这就把“顺手记一笔”从模型自觉变成了系统级的固定动作。
后台复盘如何在主任务完成后异步沉淀技能
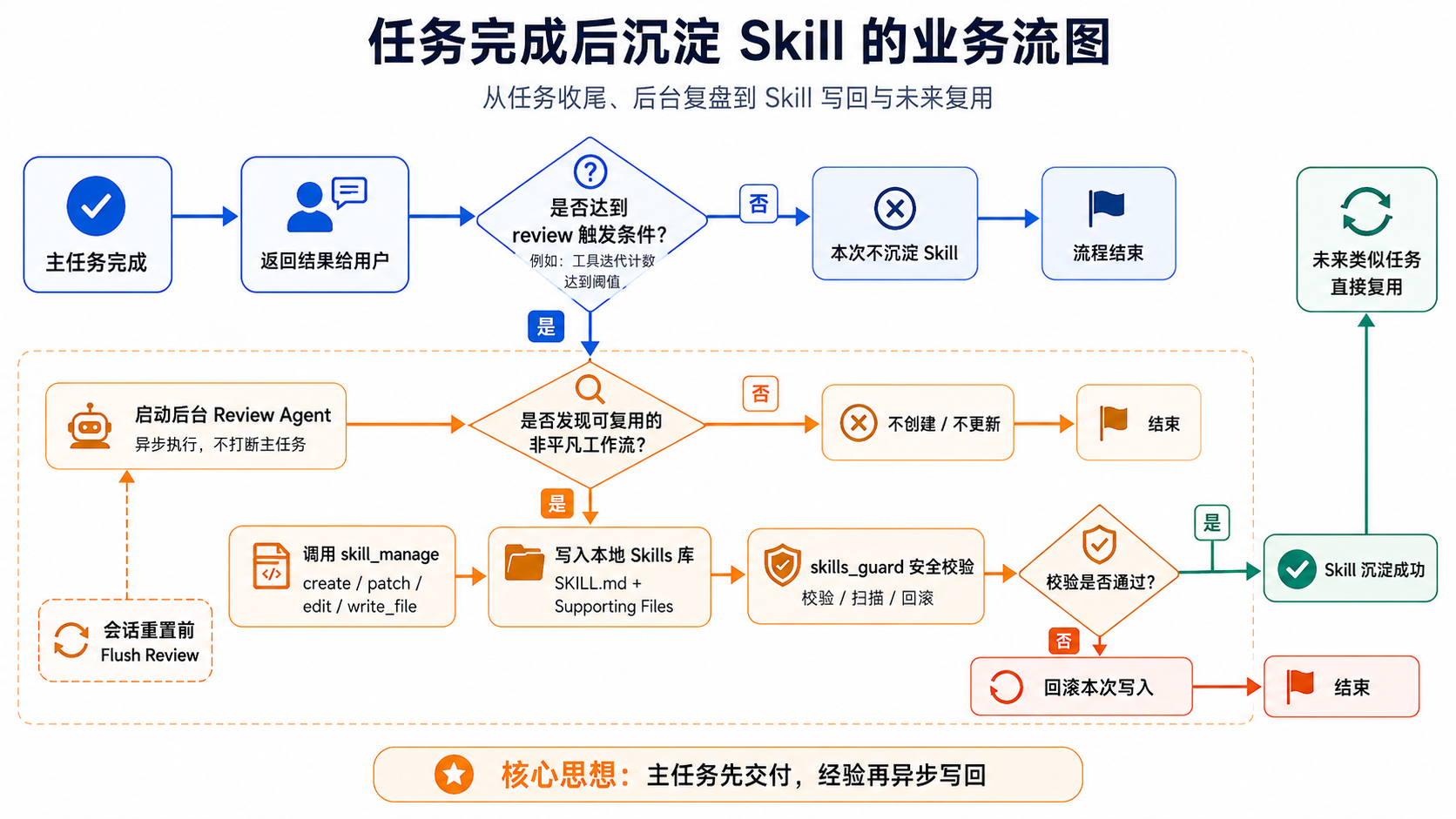
不是自治,不“裸写”:半自动背后的边界与安全
如果给这套机制一个准确的描述,就是:提示驱动、阈值触发、后台复盘、文件写回。它不是完全自治,主要有三个原因。
首先,是否值得保存仍然要靠模型判断,不会每次任务都产出新技能。其次,创建前确认用户意图更多是软约束,存在于提示和工具描述层,不是硬阻断。再者,它不是一个无限膨胀的知识工厂,重点是留下真正有复用价值的流程。
更能体现工程成熟度的,是它对写入环节的约束。只要允许 Agent 写文件,真正要关心的就不是“能不能写”,而是“写得稳不稳、边界够不够硬”。
Hermes 在 skill_manage() 的真实写入阶段做了大量校验:技能名称是否合法,分类是否合法,SKILL.md frontmatter 是否完整,内容大小是否超限,附属文件是否只写到允许的子目录,路径有没有穿越风险。写入后还会经过 skills_guard 安全扫描,不通过就回滚。尤其对 Agent 自己创建的技能,策略并不宽松,某些风险判定可能直接阻断。
技能写回不是直接落盘,而是带校验和回滚
复盘时机:后台一次,会话重置前再兜底一次
Hermes 没有在任务中途打断主流程,而是在主任务给出最终回复后,异步拉起一个轻量 Agent 做复盘。这个后台 Agent 复用当前模型和上下文快照,却不污染主会话,也不抢注意力。如果创建或更新了技能,前台只给一个很短的摘要提示。好处很直接:当前任务先完成,经验沉淀不干扰主推理,交付和复盘可以并行。
除了这种后台复盘,Hermes 还有另一道保险。当会话因为长时间不活跃或定时重置即将被清空,系统会再启动一轮清场复盘,用一个临时代理回顾整段对话,看看有没有遗漏的记忆或技能值得保存。很多复杂任务当下未必能立刻意识到是一套可复用流程,会话结束前再看一遍,等于给经验沉淀加了一层兜底。
因此,技能进化实际上有两个出口:主任务后的后台复盘和会话重置前的清场复盘。
为什么好用?工程化学习与可审计的闭环
一次复杂任务结束后,如果系统能把“什么时候该触发、先做什么后做什么、哪些命令有效、哪些坑已经踩过、最后怎么验证”这些信息留下来,下一次类似任务到来时,Agent 就不需要重新猜测,可以直接沿着上次真实跑通过的流程往前走。重复劳动少了,失败成本低了,而且因为技能是文件,人可以审查、补充、分发,团队协作也更容易。
所以我更愿意把 Hermes 的技能进化叫作“工程化学习”。它没有神秘感,但非常能落地。
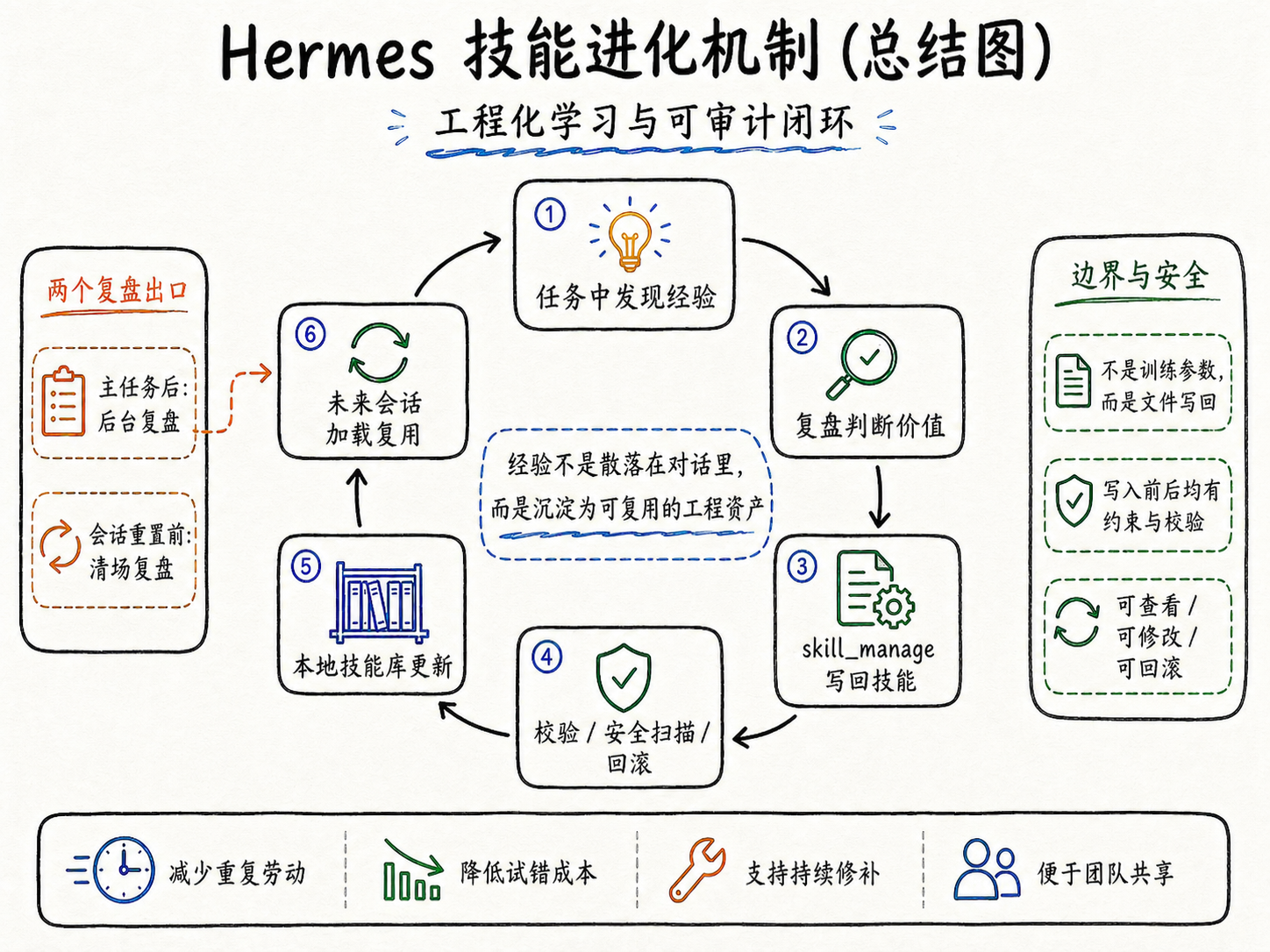
归结成一句话:Hermes 让经验以工程资产的形式留下来,而不是散落在一次次对话里。 你也可以说“Hermes 自己长出技能了”,它长出的不是参数能力,而是一份份能打开查看、能继续维护、能打补丁、也能被安全扫描的技能文件。这背后是一条非常清晰的闭环:在任务中发现经验,在任务后判断价值,用工具写回,用安全机制限制风险,在未来会话中再次加载和修补。
它没有”自治超级智能”那么夸张,却很像真正能落地的软件工程——一个 Agent 变好用,不是因为它声称自己会成长,而是因为它知道经验应当放在哪里,下一次又该怎么拿出来用。