在RAG应用中通常需要对各种文档进行文本提取,如果稳定是纯文本那文档提取会简单很多,但通常文档中会存在各种图片信息,这是就需要使用OCR在提取文档文本信息的同时对图片进行OCR获取图片中的文本内容。本文只介绍PDF文档中OCR技术方案。PDF文档解析目前有不少开源框架亦可支持对PDF中的图片进行OCR,但此类框架通常比较重如Marker、Unstructured等。
这里只使用PyMuPDF读取PDF文件并根据文档实际情况使用调用OCR进行文本提取,文本提取的质量依赖于OCR模型。PDF文档解析的速度也依赖于OCR的性能,几百页的PDF文档并不少见。
1、只提取PDF中的位图进行OCR
此方案通过解析PDF提取其内嵌的图片,只对提取的内嵌图片进行OCR,但可能会由于PDF嵌入的图片质量效果不佳或分辨率较低的问题,即使在原PDF中很清晰的图片提取出来后也是模糊不清,导致OCR准确率大大降低。特别是对于存在数学公式的PDF,提取位图进行OCR准确率极低。对图片进行二次处理如 灰度、放大、二值化、去噪后 OCR效果也不一定很理想。
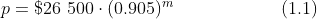
上图为PDF中的数学公式,图片为PNG格式,存在一个Alpha 通道,尽管已经分离该透明通道并填充白色背景,但是OCR识别的效果依然不佳,再进行灰度、放大、二值化、去噪后,还是效果不佳。
提取文本、提取图片进行OCR的结果、提取文本、在提取图片OCR,将文本与OCR的结果进行按原顺序作为该页的文本内容。
[{'save_path': '',
'data': [{'text': 'p=$26500:(0.905)',
'confidence': 0.8825955390930176,
'text_box_position': [[3, 4], [170, 2], [171, 14], [3, 16]]},
{'text': '1.1',
'confidence': 0.9956590533256531,
'text_box_position': [[285, 3], [313, 3], [313, 15], [285, 15]]}]}]
2、整个PDF全页都进行渲染
将PDF中每一页都进行渲染为高清位图,再对每一页进行OCR。但这将导致计算量飙升,原本800页中只有10%存在图片即需要OCR的只有80页,但这种简单粗暴的方式导致OCR计算量直接翻十倍。极端情况下可能及只有一两页文档存在图片,但此方案还是会将整个文档的每页都提交OCR,导致PDF解析速度严重缓慢,图片DPI为200-300。
3、只对PDF中的“含图页”进行渲染
在本方案中通过快速扫描PDF定位PDF中哪些页数存在图片,对这些存在图片的当前页进行渲染然后进行OCR。这样将尽可能得平衡OCR的准确率与效率,极大的降低OCR次数,释放更多性能。
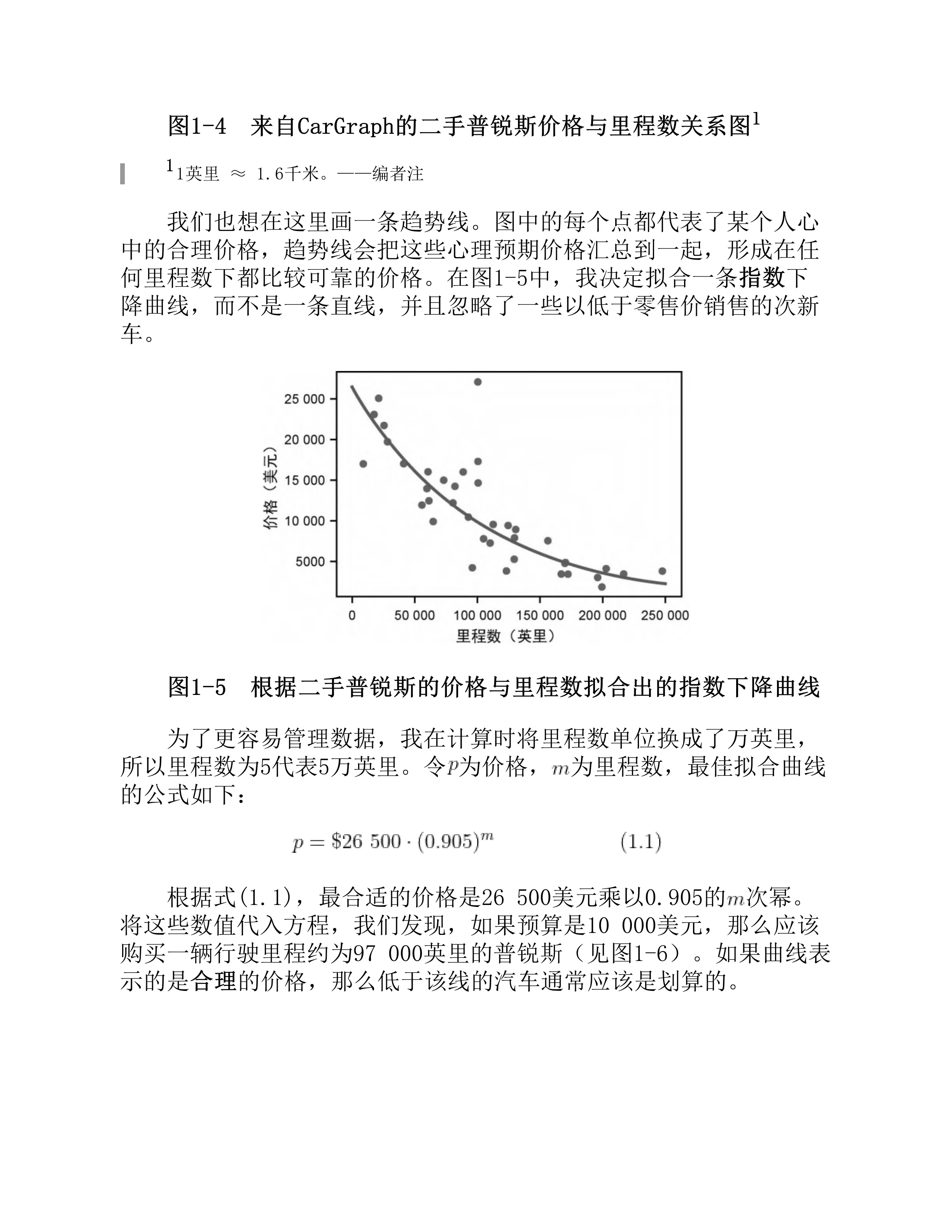
上图为对存在图片的该页渲染后得到的图片,对该图片直接进行OCR得到的结果比使用方案一对位图处理后OCR的结果还要好:
{'text': 'p = $26 500 (0.905)m', 'confidence': 0.9309449195861816,
'text_box_position': [[738, 2136], [1272, 2121], [1275, 2200], [740, 2215]]},
{'text': '(1.1)', 'confidence': 0.9146772623062134,
'text_box_position': [[1593, 2138], [1706, 2138], [1706, 2204], [1593, 2204]]}
在此方案中由于只整页进行OCR可以直接把OCR结果作为提取到的该页文本内容。而按方案一的方式需要对提取文本、提取图片进行OCR的结果、提取文本、在提取图片OCR,将文本与OCR的结果进行按原顺序作为该页的文本内容。
本方案的图片肯定会比方案一大很多,但由于OCR的次数是固定一次的,方案一图片可能会小一点但其图片数量比较多其整体性能也不一定会很高。
import fitz # PyMuPDF
def get_result(self):
"""获取pdf文件提取结果
"""
t0 = time.perf_counter()
self.extract_text()
self.extract_images()
for inx,item in enumerate(self.text_list):
if str(item).startswith('img_'):
if self.ocr_result:
ocr= self.ocr_result.pop(0)
self.text_list[inx]=ocr
logger.info(f"ocr:{self.ocr_result},images:{len(self.images_list)},txt:{len(self.text_list)}")
elapsed = time.perf_counter() - t0
logger.success(f"全部提取完成,耗时 {elapsed:.2f} 秒")
性能对比
这里选择了一个使用了**《程序员的数学.pdf》**进行解析提取文档中的文本信息以对比三种方案的性能,整个文档883页这里只解析200页内容用于性能对比。这里渲染出进行OCR的图片大小从500KB到2MB不等。
| 序号 | 方案 | 文档页数 | OCR次数(图片数) | 耗时(秒) | 说明 |
|---|---|---|---|---|---|
| 1 | 位图OCR | 200 | >=200 | - | 根据文档情况OCR次数可能最多(一页包含多张图片) |
| 2 | 每页OCR | 200 | 200 | 343.43 | 不管存不存在图片一律进行图片OCR |
| 3 | 只对图片页OCR | 200 | 139 | 223.85 | OCR次数最少 |
由于本文所使用的PDF为数学书籍包含比较多的数学公式、图表等因此包含了大量图片所以方案三和方案二的区别不是特别明显,但在图片很少的场景下两者就会有巨大的差别。存在极端情况PDF是扫描件,全部是图片方案三 退化为方案二,但整体看来方案三性能还是会好过方案二。